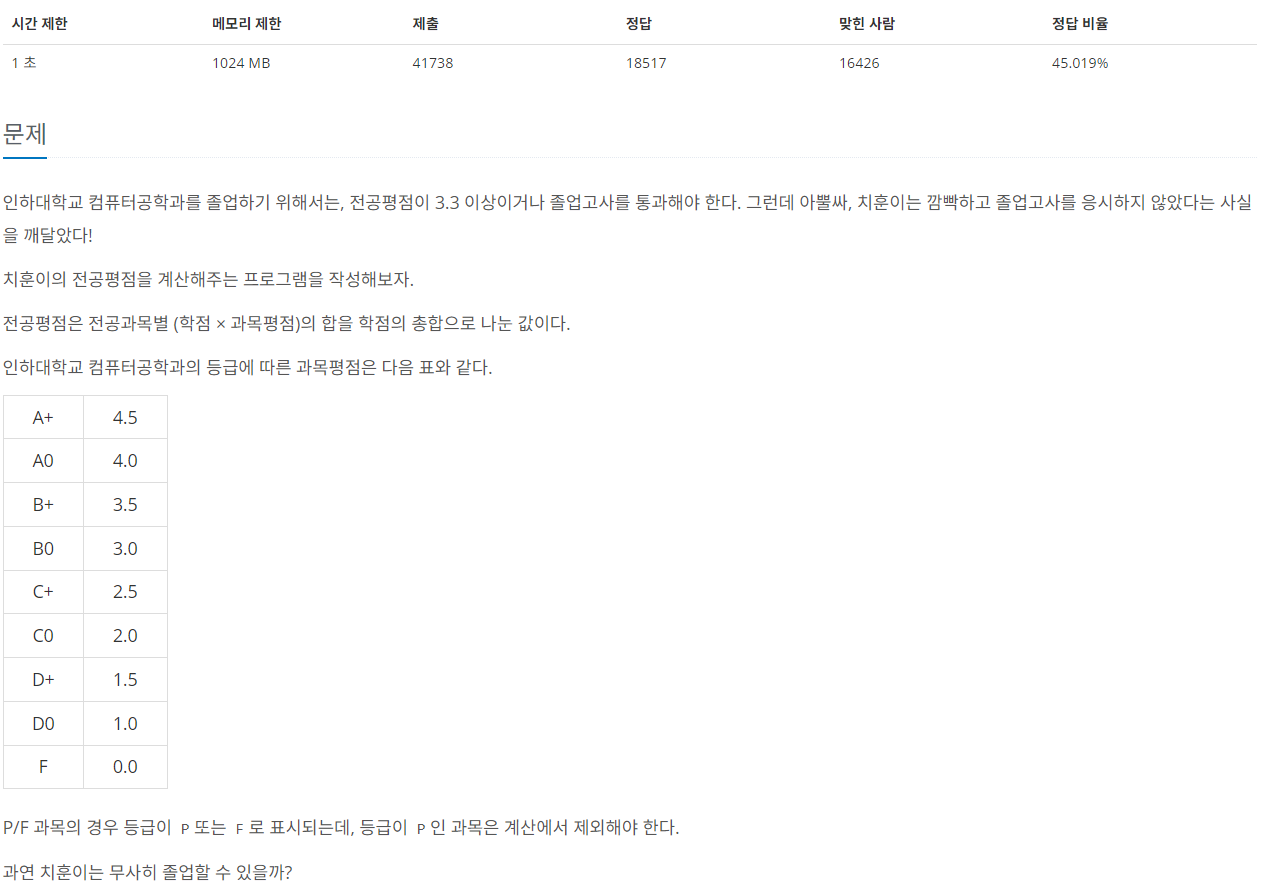
https://www.acmicpc.net/problem/25206
25206번: 너의 평점은
인하대학교 컴퓨터공학과를 졸업하기 위해서는, 전공평점이 3.3 이상이거나 졸업고사를 통과해야 한다. 그런데 아뿔싸, 치훈이는 깜빡하고 졸업고사를 응시하지 않았다는 사실을 깨달았다! 치
www.acmicpc.net
접근법
코드 방법을 두가지로 생각했었다.
1. 리스트 안에 리스트로 값을 입력 받아서([[과목명, 학점, 등급]]) p/ f면 제외.
2. 과목명은 쓸데없으니 제외하고 학점, 등급 리스트를 각각 만들어서 반복문으로 입력값을 받으면서 학점은 학점리스트, 등급은 등급리스트에 넣어주고 각 인덱스별로 등급과 학점을 뽑아서 p/ f면 제외해서 전공평점 계산.
이 문제를 풀거나 풀고 있는 사람이라면 내 접근법을 들었을 때, 어? 하는 부분이 있을것이다. 바로 p/f 제외이다. 그렇다 나는 문제를 똑바로 읽지 않은 바보라 p만 제외해야하는걸 f까지 제외하고 있었다...

1번 방법은 2번에서 생각했듯이 과목명이 필요없는데 굳이 2중 리스트를 만들 필요가 없어보여서 2번을 택해서 문제 풀이에 들어갔다.
코드 1
rank_dict = {"A+" : 4.5, "A0" : 4.0, "B+" : 3.5, "B0" : 3.0, "C+" : 2.5, "C0" : 2.0, "D+" : 1.5, "D0" : 1.0, "F": 0.0}
score = [] # 학점 4.0, 3.0...
rank = [] # 등급 A+,B,C..
for _ in range(20) :
a,b,c = input().split()
score.append(float(b))
rank.append(c)
# 학점의 총합
total_score = sum(score)
# 학점 * 과목평점의 합
score_subject = 0
for i in range(len(rank)) :
if rank[i] == 'P' or rank[i] == "F":
continue
score_subject += (score[i] * rank_dict[rank[i]])
print(score_subject / total_score)
당연히 오답. 테스트케이스에서조차 정답이 나오지 않았다. 첫 테케의 정답이 3.2844어쩌구인데 내 답은 3.072어쩌구 근소하지만 오답이었다. 매우 근소해서 코드를 유심히 째려보면서 p/f제외의 오류를 찾았다. p만 제외라니!! 이거 찾아내는데 30분이 넘게 걸렸다 ㅠㅠ
코드 2
rank_dict = {"A+" : 4.5, "A0" : 4.0, "B+" : 3.5, "B0" : 3.0, "C+" : 2.5, "C0" : 2.0, "D+" : 1.5, "D0" : 1.0, "F": 0.0}
score = [] # 학점 4.0, 3.0...
rank = [] # 등급 A+,B,C..
for _ in range(20) :
a,b,c = input().split()
score.append(float(b))
rank.append(c)
total_score = 0.0
score_subject = 0
for i in range(len(rank)) :
if rank[i] == 'P':
continue
score_subject += (score[i] * rank_dict[rank[i]])
total_score += score[i]
print(score_subject / total_score)
P등급일 경우 완전 배제를 해야하기에 sum함수로 계산해주던걸 반복문 안으로 옮겨 P 등급일 경우 계산에서 제외 시키도록 만들었다.
코드를 자세히 보면 왜 score랑 rank리스트를 썼을까 싶을 수도 있다. 왜냐면 원래 내 접근법 2번의 로직에는 딕셔너리는 존재하지 않았으니까.. 사실 딕셔너리는 푸는 과정에서 추가됐다. 각 등급별 인덱스로 접근해서 학점을 계산하는 과정에서 switch 문을 사용하려고 했었다. 파이썬으로 switch문을 사용해 본 적이 없어 문법을 위해 검색을 했는데 웬걸, 파이썬에는 switch가 없다고 한다!!
말도 안돼.. 사실 swith를 사용하는건 손의 꼽을 정도로 쓴 적이 없지만 없다고 하니 조금 충격이었다. 그 대체제로 if-elif나 딕셔너리를 보통 사용한다고 했다. 그래서 코드에 rank_dict가 추가되게 되었고 추가되는 과정에서 최적화(이럴때 쓰는 말인지는 모르겠지만 코드 효율을 높이는 과정이라고 이해해주십시오)를 하지 않아 코드가 저렇게 마무리 되었다.
글을 작성하면서 조금은 효율적으로 고쳐보고 싶다는 생각이 들어 급하게 고쳐보자면,
코드 3
rank_dict = {"A+" : 4.5, "A0" : 4.0, "B+" : 3.5, "B0" : 3.0, "C+" : 2.5, "C0" : 2.0, "D+" : 1.5, "D0" : 1.0, "F": 0.0}
total_score = 0.0 # 학점의 총합
score_subject = 0 # 학점 * 과목평점
for _ in range(20) :
subject_name, score, rank = input().split()
if rank == "P" :
continue
score_subject += float(score) * rank_dict[rank]
total_score += float(score)
print(score_subject / total_score)
이렇게 최적화를 할 수 있을 듯하다. input()과정에서 문자열로 들어왔기 때문에 float를 해줘서 실수로 바꿔주는걸 제외하고는 바뀐게 없다.
'알고리즘' 카테고리의 다른 글
| 백준 1316 그룹 단어 체커 파이썬 풀이 (0) | 2024.01.16 |
|---|---|
| 백준 9012 괄호 파이썬 풀이 (2) | 2024.01.15 |
| 백준 2839 설탕 배달 파이썬 풀이 (2) | 2024.01.12 |
| 백준 2556번 별 찍기 - 14 파이썬 풀이 (0) | 2024.01.12 |
| 백준 2440번 별 찍기 - 3 파이썬 풀이 (0) | 2024.01.12 |